01.06.2023
Ein umfassender Blick in den Werkzeugkasten
Kubernetes Basics: Der Aufbau einer Plattform mit Kubernetes
Kubernetes ist eine umfangreiche Technologie, die auch erfahrene Entwickler immer wieder vor neue Herausforderungen stellt. Deshalb haben zahlreiche Anbieter Tools entwickelt, um die Arbeit mit und um Kubernetes zu erleichtern.
Wir werfen einen Blick in den Werkzeugkasten, erläutern Einsatzmöglichkeiten der verschiedenen Tools und geben Beispiele, welche Lösungen angeboten werden.

Table of contents
Kubernetes ist eine Open-Source-Technologie, um containerisierte Software zu verwalten und hilft Entwicklern dabei, einzelne Anwendungen für die Endnutzer hochverfügbar zu halten.
Die Technologie Kubernetes kann durch Entwickler vollkommen eigenständig genutzt werden - eben um “nur” Software zu verwalten. Eine Applikation kann dann i.d.R. eigenständig auf dem Cluster ausgeführt werden. Soll diese Applikation jedoch nicht nur im Cluster ausgeführt werden, sondern auch “von außen” erreichbar sein, z.B. durch einen Endanwender, ist zusätzlich zu Kubernetes noch eine Technologie wie Ingress notwendig. Damit beginnt schon der Aufbau einer ganzen Plattform.
Kubernetes kann mit einer Vielzahl eigenständiger Applikationen und anderen Technologien ergänzt werden, um so eine beliebig komplexe Plattform aufzubauen, bei der Kubernetes dann ein zentraler Bestandteil ist. Solche Plattformen können ganz individuelle Entwicklungsprozesse abbilden, je nachdem, wie einzelne Teams ihre Prozesse organisieren oder welche Unternehmensanforderungen abgebildet werden sollen.
In diesem Text wollen wir einzelne Technologien und Applikationen, die für den Aufbau einer solchen Plattform in Frage kommen, vorstellen und erläutern. Unsere Zielgruppe dabei sind einerseits Entwickler, die noch keine Erfahrung mit Kubernetes haben, andererseits aber auch Personen, die zwar im Feld der Softwareentwicklung tätig sind, aber selbst nicht entwickeln, sondern z.B. Projekte managen.
Die Liste der hier vorgestellten Applikationen und Technologien stellt dabei nur eine Auswahl der Möglichkeiten für einzelne Teilbereiche dar und ist nicht abschließend.
Managed Cluster und Kubernetes-Distributionen
Managed Kubernetes-Cluster
Was machen Managed Kubernetes-Cluster?
Wie bereits in dem Artikel Kubernetes für Anfänger, handelt es sich bei Kubernetes (abgekürzt auch k8s) um eine Open-Source-Technologie, die von jedem frei genutzt werden kann. Zusätzlich gibt es aber noch Anbieter von so genannten managed Kubernetes-Clustern, die für die Nutzung von Kubernetes sowohl die Infrastruktur als auch eine erste Benutzeroberfläche bereitstellen.
Welche Manageds Kubernetes-Cluster Anbieter gibt es?
Die bekanntesten Anbieter für managed Kubernetes-Cluster sind Azure Kubernetes Service (AKS), Google Kubernetes Engine (GKE) and Amazon Elastic Kubernetes Service (EKS).
Alle Anbieter stellen für die Arbeit mit Kubernetes eine Benutzeroberfläche und weitere Services bereit. Ob einzelne Services bereits im Basispreis enthalten sind oder über Lizenzen noch weiter zugekauft werden müssen, variiert stark je nach Anbieter.
Im Einzelfall sollte von den Entwicklern geprüft werden, welche Services einzelne Anbieter zur Verfügung stellen und ob diese notwendig und sinnvoll sind. AKS beispielsweise stellt in der Basis-Version bereits ein gutes Logging zur Verfügung, bei EKS muss ein solches zusätzlich zur Basisversion erworben werden.
Kubernetes-Distributionen
Was sind Kubernetes-Distributionen?
Die Abgrenzung zwischen Anbietern von managed Kubernetes-Clustern und Anbietern von Kubernetes Distributionen ist nicht ganz einfach.
Ein Kubernetes-Cluster mit den notwendigen Nodes und Pods kann vollständig autonom betrieben werden. Dazu bedarf es auch nicht der Nutzung eines managed Clusters.
Die im weiteren Verlauf dieses Textes beschriebenen Tools können, müssen aber nicht zwangsläufig genutzt werden, wenn man einen Kubernetes-Cluster betreibt. Durch die Nutzung dieser Tools können beliebig komplexe Plattformen erstellt werden, deren Kernstück der Kubernetes-Cluster ist. Diese Tools wollen wir im Folgenden als “Ecosystem-Tool” bezeichnen.
Anbieter von Kubernetes-Distributionen stellen eine bereits vordefinierte Plattform mit einzelnen Ecosystem-Tools zur Verfügung. Anbieter von managed Kubernetes-Clustern hingegen stellen demgegenüber für die Nutzung von Kubernetes “nur” die Infrastruktur und eine erste Benutzeroberfläche mit einzelnen Funktionen zur Verfügung, die um beliebige Ecosystem-Tools erweitert werden können.
Kubernetes-Distributionen bieten den Mehrwert, dass Entwickler diese Tools nicht selbst in den Cluster integrieren müssen. Es ist davon auszugehen, dass alle in dieser Plattform genutzten Tools untereinander und mit dem Kubernetes-Cluster aufeinander abgestimmt konfiguriert sind, automatisiert regelmäßige Updates erhalten und somit fehlerfrei ausgeführt werden.
Es steht den Entwicklern aber frei, diese Plattformen wiederum in einen managed Kubernetes-Cluster zu integrieren und einige Anbieter von managed Kubernetes-Clustern bieten auch bereits eine Kubernetes-Distribution an.
Zusammengefasst kann man also sagen, dass managed Kubernetes-Cluster ein vorgefertigtes Grundgerüst für die Arbeit mit Kubernetes zur Verfügung stellen. Kubernetes-Distributionen gehen einen Schritt weiter und liefern zusätzlich bereits integrierte Tools als Paket.
Welche Anbieter von Kubernetes-Distributionen gibt es?
Die bekanntesten Anbieter für eine Kubernetes-Distribution sind wahrscheinlich Red Hat OpenShift und Rancher Kubernetes Engine (RKE).
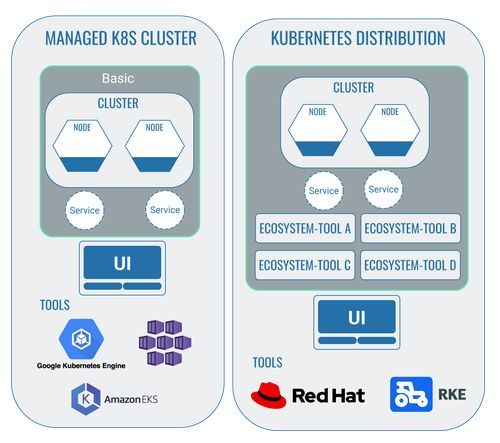
Technologien, die in einem Kubernetes-Cluster installiert werden
Kubernetes Dashboard: Das Standard-Frontend
Was ist das Kubernetes Dashboard?
Beim Kubernetes Dashboard handelt es sich um ein web-basiertes User-Interface. Kubernetes Dashboard ist ein Bestandteil von Kubernetes und bietet eine Benutzeroberfläche um beispielsweise containerisierte Software auf einen Cluster zu deployen oder dessen Ressourcen zu managen. Man bekommt damit einen Überblick über alle Applikationen und Services, die in einem Cluster laufen oder kann individuelle Kubernetes Ressourcen (wie Jobs, Deployments, etc.) modifizieren.
Kubernetes Dashboard als Benutzeroberfläche ist aber nicht per Default in einem Cluster installiert, sondern muss explizit dafür ausgewählt werden.
Ein Kubernetes Cluster kann auch ohne das Kubernetes Dashboard über die Kommandozeile verwaltet und gemonitored werden. Die Bedienbarkeit wird durch das Dashboard aber wesentlich vereinfacht.
Welche Tools gibt es?
Das Kubernetes Dashboard ist das Standard-Frontend für einen Kubernetes-Cluster. Alternativ bieten auch Anbieter von managed Clustern wie AKS oder GKE ein eigenes Dashboard an.
Kommandozeilentool: Technologien, um mit einem Cluster zu kommunizieren
Was sind Kommandozeilentools?
Einen Cluster muss man sich zwar als eigenständiges, in sich abgeschlossenes Gebilde vorstellen, aber unabhängig von seiner Umgebung ist ein Cluster dennoch nicht. Ein Cluster macht nur das, was ihm als Kommando vorgegeben wird. Es muss also einen Weg geben, wie Entwickler mit dem Cluster kommunizieren können.
Dafür gibt es Benutzeroberflächen, die Informationen zum Cluster gebündelt darstellen können und es Entwicklern erlauben, mit dem Cluster in Verbindung zu treten. Allerdings arbeiten die meisten Entwickler gerne mit sogenannten Komandozeilentools: Informationen können ohne große grafische Aufbereitung abgefragt oder an den Cluster weitergegeben werden.
Kommandozeilentools muss man sich wie integrierte Entwicklungsumgebungen bei der Softwareentwicklung vorstellen: Verschiedenen Tools haben einen unterschiedlichen Funktionsumfang und legen ihren jeweiligen Fokus auf unterschiedliche Anwendungsbereiche (siehe z.B. "Was ist eine IDE?"). Analog dazu gibt es auch unterschiedliche Kommandozeilentools, die die Entwickler je nach Präferenz für die Arbeit mit einem Kubernetes-Cluster nutzen können.
Welche Komandozeilentools gibt es?
Tools, die hier zur Verfügung stehen, sind beispielsweise kubectl, kubectx oder kube-shell.
Um eine Analogie zum Auto zu bemühen, kann man sich vorstellen, dass Kubernetes selbst das Konzept der Autotür beinhaltet, über die Entwickler mit einem Kubernetes-Cluster in Verbindung treten können. Kommandozeilentools wiederum setzten das Konzept der Tür unterschiedlich um: Einmal öffnet sich die Türe nach vorne, einmal nach hinten und das dritte Tool ist eine Flügeltüre. Welches Kommandozeilentool genutzt wird, ist aber grundsätzlich egal und liegt in der Entscheidung der Entwickler. Unterschiedliche Entwickler, die aber mit dem gleichen Cluster arbeiten, können auch unterschiedliche Kommandozeilentools benutzen.
Service-Mesh: Technologie, um die Kommunikation zwischen Cluster-Bestandteilen zu managen
Was machen Service-Meshes?
“Klassische” Anwendungen sind eher in der Form eines Monolithen konzipiert. “Moderne” cloud-native Anwendungsarchitekturen hingegen setzen auf einzelne Microservices und die Anwendung entsteht erst durch eine Verflechtung und Interaktion einzelner Microservices untereinander. Einzelne Services sind in Container verpackt, die in einzelnen Pods zusammengefasst sind, welche wiederum miteinander kommunizieren und Informationen austauschen (siehe dazu "Kubernetes für Anfänger").
Die Kommunikation zwischen einzelnen Pods (,die den containerisierten Code enthalten) erfolgt in einem Kubernetes Cluster selbst und wird durch die Entwickler definiert. Zusätzlich kann durch die Entwickler noch ein sogenanntes Service Mesh eingesetzt werden, das es erlaubt, die Kommunikation zwischen Pods noch genauer zu spezifizieren.
Um das zu veranschaulichen, wollen wir uns an dieser Stelle einen Online-Shop vorstellen. Dem Kunden stehen beim Checkout beispielsweise 2 Zahlungsmöglichkeiten zur Verfügung: auf Rechnung und per Kreditkarte. Die Shopbetreiber wollen künftig aber auch die Bezahlung per Paypal möglich machen. Nachdem die Entwickler den dafür notwendigen Code erarbeitet und in einer Testumgebung geprüft haben, soll es nun einen ersten Test im Live-Shop geben.
Durch die Nutzung eines Service-Mesh kann die Neuentwicklung (Auswahl zwischen 3 Zahlungsmöglichkeiten) auf einem eigenen Pod im Cluster zur Verfügung gestellt werden. Die ursprüngliche Umsetzung (Auswahl nur zwischen 2 Zahlungsmöglichkeiten) kann im Cluster aber bestehen bleiben. Mit dem Service-Mesh können die Entwickler definieren, dass 80% der eingehenden Anfrage weiterhin auf den Pod mit dem ursprünglichen Stand (Auswahl nur von 2 Zahlungsmöglichkeiten) geleitet wird und nur 20% auf den Pod mit der Neuentwicklung.
Service-Meshes können aber noch mehr: Im obigen Beispiel wird über Service-Meshes definiert, was an die einzelnen Pods kommuniziert wird. Über Service-Meshes kann aber auch definiert werden, wie innerhalb des Clusters kommuniziert wird. Grundsätzlich ist die Kommunikation im Cluster beispielsweise nicht verschlüsselt, durch Service-Meshes kann eine zusätzliche Verschlüsselung definiert werden.
Welche Service-Meshes Tools gibt es?
Tools, die die Technologie des Service-Mash bereitstellen, sind beispielsweise Istio, Linkerd oder Cilium.
Diese Tool stellen jeweils wieder einen unterschiedlichen Umfang an nutzbaren Möglichkeiten dar. Linkerd verfügt beispielsweise über sogenannte “Sidecar Proxies”, die den Aufbau einer verschlüsselten Kommunikation der Pods untereinander im Cluster erlauben. Istio hingegen bietet diese Funktion nicht. Dafür ist Istio im Vergleich zu Linkerd weniger komplex, in der Architektur schlanker und erfordert keine Code-Änderungen an der Kubernetes-Applikation selbst. Welches das Mittel der Wahl ist, muss also im Einzelfall durch die Entwickler geprüft und beurteilt werden (siehe auch "Was ist Linkerd").
Ingress-Controller: Technologie um Anfragen an den Cluster zu kontrollieren
Was bedeutet Ingress?
‘Ingress traffic’ bezeichnet den Datenverkehr, der seinen Ursprung außerhalb eines Computernetzwerks hat und an dieses gerichtet ist. Bezogen auf einen Cluster bedeutet das, dass eine Anfrage von außerhalb des Clusters an diesen gestellt wird, also z.B. dass ein User eine Website oder einen Service aufruft, der in einem Cluster betrieben wird. Die Technologie oder Ressource “Ingress” macht HTTP- und HTTPS-Anfragen von außerhalb des Clusters für Dienste innerhalb des Clusters verfügbar.
Analog zum technischen Konzept von Kubernetes handelt es sich auch bei der Technologie “Ingress” um einen abstrakten technischen Bauplan. Die genaue Umsetzung des technischen Bauplans von Ingress liegt wieder beim jeweiligen Hersteller. Um auch hier die Analogie des Autos zu nutzen, liegt es in der Entscheidung des jeweiligen Autobauers, ob der Motor als Verbrennungs- oder Elektromotor umgesetzt wird.
Ingress selbst ist also das Konzept, wie externe Anfrage an einen Kubernetes-Cluster gestellt werden. Dazu zählt zum Beispiel, wie die Anzahl der externen Anfragen im Kubernetes Cluster ausbalanciert werden, oder dass einer im Cluster verfügbaren Applikation überhaupt eine von extern erreichbare URL zugewiesen wird. Die Ausführung des Konzepts liegt dann bei einem so genannten Ingress-Controller, also der Anbieter-spezifischen Ausgestaltung von Ingress.
Ingress-Controller sind dabei nicht nur in Zusammenhang mit Kubernetes-Clustern relevant, sondern für die Nutzung von allen Services, die innerhalb eines Computernetzwerkes für Datenverkehr von außen ansprechbar sein sollen - also auch für Services, die auf individuellen Servern gehostet werden.
Welche Ingress-Controller gibt es?
Es gibt eine ganze Reihe an verfügbaren Ingress controllers. Zu den bekanntesten und in Kombination mit Kubernetes-Clustern häufig verwendeten Ingress-Controllern zählen Nginx und Traefik.
Beide haben wieder diverse Vor- und Nachteile, je nach Anwendungsfall. Welcher Ingress-Controller genutzt werden soll, muss zwingend von spezialisierten Entwicklern beurteilt werden und würde den Rahmen dieses Artikels bei weitem übersteigen. Wir können euch jedoch diese beiden Artikel über Ingress und Ingress controllers von der Kubernetes-Website empfehlen, damit ihr eure Research fortsetzen könnt.
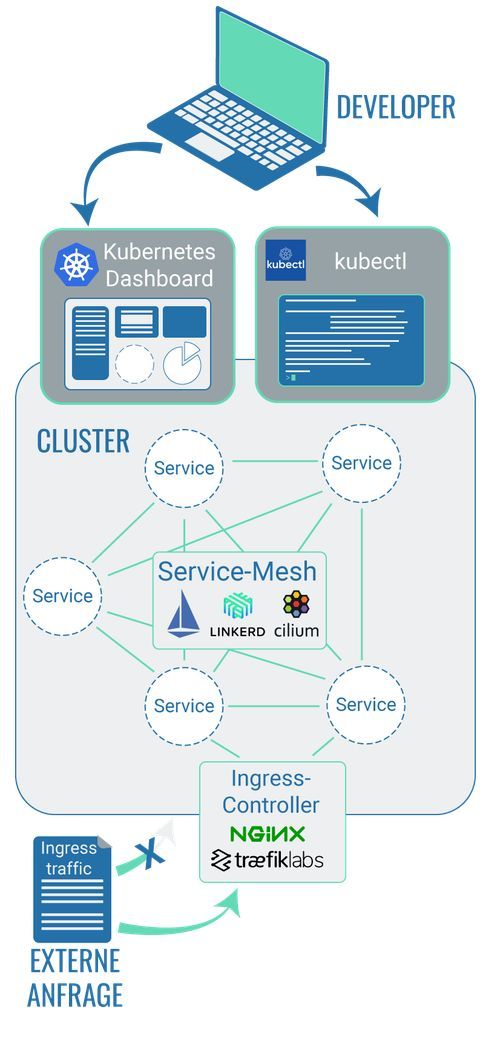
Technologien, die um einen Kubernetes-Cluster herum installiert werden
Technologien, um Code in Container zu verpacken
Container Images
Kubernetes ist eine Technologie um containerisierte Software zu orchestrieren. Siehe dazu auch unseren Blog Posts Kubernetes für Anfänger, um mehr über dieses Thema zu erfahren. Ohne containerisierte Software ist die Nutzung von Kubernetes selbst gegenstandslos - eben weil Kubernetes nur mit containerisierter Software arbeiten kann.
Nachdem der Code für eine Anwendung durch Entwickler erarbeitet wurde, wird daraus ein sogenanntes ‘container image’ erstellt. In Kubernetes wird dann später auf das jeweilige Container Image referenziert. Verwaltet werden die Container Images entweder in einer eigenständigen Container Registry außerhalb des Clusters oder direkt im Cluster selbst. Erst wenn dieses referenzierte Container Image in Kubernetes ausgeführt wird, wird es technisch gesehen zu einem eigenständigen Container.
Ein Container Image ist ein read-only Template des Codes einer Anwendung, inklusive aller notwendigen Informationen, die für das Ausführen des Codes relevant sind, z.B. Konfigurationsdateien, Umgebungsvariablen, Bibliotheken, etc. Man kann sich ein Container Image also als unveränderliches digitales Bild des Codes vorstellen. Der Vorteil von Container Images liegt darin, dass sie dupliziert und von mehreren Entwickler gemeinsam genutzt werden können. Damit sind Container Images die idealen Ressourcen, um in einem Cluster geteilt zu werden. Anwendungscode kann so innerhalb eines Clusters zum Beispiel auf mehreren Pods ausgeführt und damit skaliert werden.
Ein weiterer Vorteil der Nutzung von Container Images besteht darin, dass das Image die Konfigurationen für die später entstehenden Container gleich enthält. Anders als bei der Ausführung von Softwarecode auf einem eigenen Server erhalten die Container mit den Informationen aus den Images direkt alle notwendigen Konfigurationsinformationen. Alle später auf Basis des Images generierten Container sind damit immer gleich konfiguriert. Wird Softwarecode auf jeweils eigenen Servern ausgeführt, muss die Konfiguration für jeden Server neu und einzeln vorgenommen werden - ein fehleranfälliges und zeitaufwändiges Vorgehen. Informiere dich sich weiter über Docker Images
Tools zur Erstellung von Container Images
Der bekannteste Anbieter von Tools, um aus Softwarecode ein Container-Image zu erstellen, ist Docker. Mit Docker oder anderen Tools, wie rkt von CoreOS oder LXC, wird ein Container Image erstellt.
Bei Docker handelt es sich um ein virtualisiertes Betriebssystem für Container und verhält sich ähnlich wie eine Virtuelle Maschine (VM). Eine VM virtualisiert dabei Serverhardware, während Container das Betriebssystem eines Servers virtualisieren.
Erhalte hier einen guten Überblick über verschiedene Anbieter mit Vor- und Nachteilen im Vergleich zu Docker als Marktführer. Welches Tool zur Umsetzung dieser Technologie genutzt wird, hängt wesentlich von den technischen Voraussetzung und Präferenz der jeweiligen Entwickler ab (z.B. wird mit Windows, Linux oder Mac gearbeitet?).
Zur Verwaltung von Container Images kann beispielsweise quay.io, genutzt werden. Eine Reihe von Anbietern alternativer Tools zu quay.io findet sich heir Hervorheben möchten wir das Tool Harbor. Während es sich bei quay.io um ein Tool handelt, das eine Container Registry außerhalb des Cluster bereitstellt, kann Harbor direkt in den Cluster installiert werden und die Verwaltung der Images erfolgt damit auch direkt im Cluster. Ein zusätzlicher externer Dienst außerhalb des Clusters ist damit nicht mehr notwendig. Welche Variante hier sinnvoller ist, ist eine Entscheidung des Entwicklerteams und hängt von den individuellen Anforderungen an die zu erstellende Software ab.
Technologien, um Apps und Konfigurationen in einem Cluster zu managen
Konfiguration eines Clusters mit yaml-Dateien
Nur weil ein Cluster existiert, ist er aber noch nicht sofort für den produktiven Betrieb bereit. Jeder Cluster verfügt über eine spezifische Konfiguration und jede neue Applikation in einem Cluster muss diese Konfiguration berücksichtigen, damit sie korrekt ausgeführt werden kann.
Die Konfiguration eines Clusters wird in sogenannten yaml-Dateien definiert. Yaml-Dateien enthalten Spezifikationen für das Deployment.
Sie können händisch durch die Entwickler erstellt werden. Nachteilig ist dabei, dass ein händisches Erstellen von Dateien grundsätzlich fehleranfällig ist. Zusätzlich benötigt ein komplexer Cluster mehrere yaml-Dateien, die alle dem gleichen Standard folgen müssen. Das bedeutet, dass jeder Entwickler in einem Team den Standard auch kennen und anwenden muss. Wird der Standard geändert, benötigt es zusätzliche Absprachen.
Um diesen Prozess effizienter, stabiler und effektiver zu gestalten, gibt es Tools, die Templates zur Verfügung stellen, so dass alle yaml-Dateien “gleich aussehen”.
Helm zur Erzeugung von yaml-Dateien
Das bekannteste Tool, das außerhalb eines Clusters installiert wird, um yaml-Dateien zu erzeugen, ist Helm.
In sogenannten Helm Charts wird definiert, welche Abhängigkeiten zwischen den einzelnen Applikationen innerhalb des Cluster bestehen, welche Ressourcen aus Kubernetes benötigt werden und was sonst noch notwendig ist, um Container-Anwendungen bereitzustellen und auszuführen.
Ein Helm Chart kann dabei beliebig oft im Cluster genutzt werden um beliebig viele Instanzen einer Anwendung zu realisieren und das System so leicht zu skalieren (siehe auch "Was ist Helm?").
Helm Charts können auch mit anderen Personen geteilt werden. Sie sind also die zentrale Instanz um eine Anwendung einmalig zu definieren und dann mit minimalem Aufwand von vielen Personen verwalten zu lassen.
Technologien zur lokalen Ausführung von Kubernetes
Softwareentwicklung auf lokalen Rechnern
Dazu machen wir einen ganz kurzen Ausflug in die Arbeitswelt der Entwickler. In der Regel werden einzelne Bestandteile eines komplexen Codes entwickelt, einzelne Features, die später zusammengeführt werden. Entwickler produzieren Code also lokal auf ihren eigenen Rechnern und nicht direkt in komplexen Produktiv- oder Testumgebungen. Erst später werden die einzelnen Bestandteile dann zusammengeführt.
Dafür ist notwendig, dass Entwickler die projektspezifische Entwicklungsumgebung auf ihren eigenen Rechnern verfügbar haben, also die Rahmenkonfigurationen der späteren Test- und Produktivumgebung. Das ist immer notwendig, egal ob für den späteren Betrieb der Software Kubernetes genutzt wird oder nicht.
Die Herausforderung für die Entwickler liegt darin, diese Umgebung auf ihren lokalen Rechner richtig zu konfigurieren. Nur wenn gegen die richtige Konfiguration entwickelt wird, kann der Code später in der Produktiv- oder Testumgebung auch fehlerfrei ausgeführt werden. Bisher lag die große Herausforderung darin, dass jeder einzelne Entwickler die entsprechenden Konfigurationen selbst vornehmen musste. Enge Absprachen zwischen den Teams, die Software entwickeln (Development-Teams), und den Teams, die für die Konfiguration der später genutzten Server zuständig sind (Operations-Teams), sind dafür notwendig. Die Kommunikation zwischen beiden Teams läuft dabei oft nicht reibungslos.
Wird für die Ausführung von Softwarecode Kubernetes genutzt, gibt es nun aber eine ganze Reihe von Tools, die es ermöglichen, dass das Operations-Team die Konfiguration des Cluster selbstständig vornimmt, pflegt und wartet und die Entwicklerteams die Konfigurationen durch den Einsatz spezialisierter Tools ohne selbstständig Konfigurationsmaßnahmen oder notwendigen Absprachen auf ihren Rechner installieren können. Auch wenn sich die Konfigurationen am Cluster ändern, ermöglichen diese Tools, dass die geänderten Konfigurationen ohne weitere Absprachen zwischen den Teams auch auf die Rechner der Entwickler übernommen werden.
Lokale Kubernetes Entwicklungstools
Beispiele für Tools, die diese Technologie anbieten, sind minikube, kind oder auch K3s.
Einen guten Überblick über die unterschiedlichen Umfänge dieser Tools und mögliche Anwendungsfälle findet sich hier.
Technologien, um Container zu “bridgen”
Was bedeutet 'bridgen'?
Zuerst müssen wir voranstellen, dass das Wort “bridgen” keine anerkannte Terminologie ist, um zu beschreiben, was die hier vorgestellten Tools machen. Um ehrlich zu sein: Wir haben den Begriff bei uns eingeführt, weil er den Zweck dieser Technologien sehr anschaulich beschreibt. Wenn ihr also das Internet nach dem Terminus “bridgen” in Zusammenhang mit Kubernetes durchsucht, werdet ihr vermutlich kaum sinnvolle Treffer erhalten. Daher möchten wir an dieser Stelle den Terminus “bridgen” und die dazugehörigen Tools näher vorstellen.
Um einen Cluster zu betreiben, bedarf es einiger Ressourcen: Vor allem Rechenleistung. Und Rechenleistung kostet Geld. Geld ist nicht unbegrenzt verfügbar und dass es sowohl in der kommerziellen als auch nicht-kommerziellen Softwareentwicklung nicht unbegrenzt verfügbar ist, müssen wir hier nicht philosophisch erörtern.
Auch wenn Entwickler einen Cluster bei sich lokal verfügbar machen, um die Softwareentwicklung selbst effektiver zu gestalten, kostet das Ressourcen und damit Geld. Man stelle sich nur vor, dass ein großes Entwicklerteam an einer Vielzahl kleinerer neuer Features für eine große Hotelbuchungsplattform arbeitet und dass jeder Entwickler einen lokal verfügbaren Cluster besitzt, um einen Vorstellung von der Größenordnung der notwendigen Ressourcen zu bekommen.
Auch um dieses Problem zu lösen, gibt es eine maßgeschneiderte Technologie. Installieren sich Entwickler ein Tool dieser Technologie lokal auf ihren Rechnern ist es möglich, dass sie den Code lokal entwickeln und in Containern verpacken, bei der Ausführung des Codes im Container auf den eigenen Rechner dem Container aber "vorgegaukelt" wird, er würde sich in einem Cluster befinden.
Dieses “Vorgaukeln” ist aber noch nicht das, was “bridgen” eigentlich meint. Bridgen beginnt technisch gesehen erst, wenn Entwickler an bereits bestehenden Code arbeiten, zum Beispiel um einen Bugfix auszuführen. Dabei kann ein Entwickler mit den entsprechenden Tools (siehe unten) einen Container auf seinem lokalen Rechner “klonen” und an bereits bestehenden Code arbeiten. Der überarbeitete Code kann im bestehenden Cluster auf einen Container gelegt und getestet werden, wobei er noch immer ausschließlich auf dem lokalen System des Entwicklers ausgeführt wird. Solange diese Bridge besteht, können alle User, die über die URL verfügen, auch auf diese Code-Änderung zugreifen.
Dabei ist aber zu bedenken, dass aller Traffic auf diesen Container dann auch über die lokale Entwicklungsumgebung des jeweiligen Entwicklers geht, dieses Verfahren ist also vor allem sinnvoll, um Arbeiten in einem Staging-Cluster durchzuführen: Bugfixes können damit direkt im Staging getestet werden. Für Arbeiten an einem Produktivcluster sollte dieses Verfahren eher nicht angewendet werden.
Welche Bridging-Tools gibt es?
Eines der bekanntesten Tools zum Bridgen ist “Telepresence”.
Blueshoe hat für diese Zwecke auch ein eigenes Tool namens ‘Gefyra’ entwickelt. Gefyra ist zwar hinsichtlich der Funktionalitäten nicht ganz so umfangreich wie Telepresence, ist mit seinem Fokus in der Nutzung aber wesentlich komfortabler für die Entwickler bei der Erstellung einer Bridge. Eine Gegenüberstellung beider Produkte könnt ihr im Blog Post "An Alternative to Telepresence 2: Gefyra".
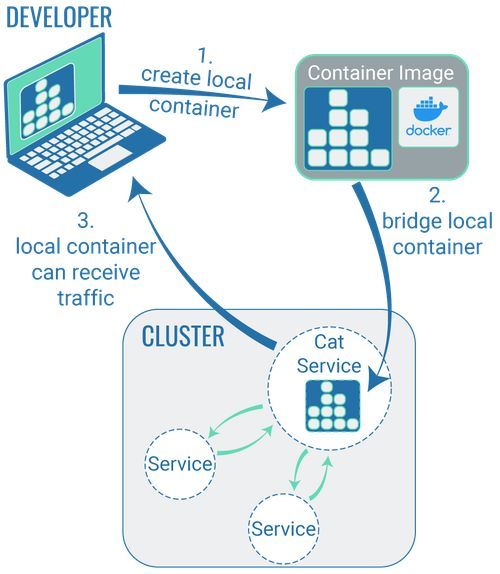
Technologien, um den Entwicklern eine Entwicklungsumgebung zur Verfügung zu stellen, die der Produktionsumgebung entspricht
Anforderungen an die Entwicklungsumgebung
Sind Arbeiten an Softwarecode erforderlich, der in einem Cluster ausgeführt wird, ist es notwendig, dass die Entwickler in der lokalen Entwicklungsumgebung ebenfalls über einen Cluster verfügen.
Dafür ist es sinnvoll, dass der lokale Cluster in der Konfiguration weitgehend dem Cluster entspricht, auf dem der Softwarecode später ausgeführt wird. Dafür gibt es Tools wie z.B. minikube (siehe oben).
Zusätzlich ist es genauso sinnvoll, wenn der lokale Entwicklungscluster auch "vorgefüllt" ist, d.h. dass die im Cluster vorhandenen Daten ebenfalls weitgehend den Livedaten entsprechen. Dazu gehören zum Beispiel Datenbanken, Datenbankeinträge, integrierte Drittsysteme, wie zum Beispiel Tools zum Identifikationsmanagement, etc..
Das heißt, wir haben einerseits Tools, damit Cluster auf den lokalen Entwicklungsumgebung einzelner Entwickler erstellt werden können. Diese Tools stellen sicher, dass alle Entwickler jeweils über die gleichen Konfigurationen verfügen. Ein Beispiel dafür ist zum Beispiel minikube (siehe oben).
Andere Tools erlauben es den Entwicklern, bereits bestehenden Code im lokalen Entwicklungscluster zu bearbeiten und diesen Code dann vor dem Deployment im Cluster “auszuprobieren”. Beispieltools dafür sind “Telepresence” oder “Gefyra” (siehe oben).
Und dann gibt es noch die in diesem Abschnitt vorgestellten Tools, die es erlauben, lokale Cluster mit Daten und/oder Drittsystemen, die möglichst nahe am Livesystem sind, für die Entwickler zu provisionieren.
Welche Tools gibt es?
Ein Tool, das die Vorprovisionierung von lokalen Clustern erlaubt, ist das von Blueshoe entwickelte Tool “Getdeck”. Wir sind von unserem Tool überzeugt und wenden es in unserer täglichen Arbeit an - gerne könnt ihr einen Termin mit uns buchen, in dem wir euch Getdeck näher vorstellen.
Technologien, um die Code-Qualität sicherzustellen
Vorteile von CI/CD
Als Software nur auf Medien wie Disketten oder CD-Roms zur Verfügung stand, lag der Fokus für Entwickler auf der Erarbeitung einer dauerhaften Version von Software. Gab es ein Update, musste sich der User eine neue CD-Rom mit dem aktualisierten Code-Stand besorgen.
Heute ist dieses Vorgehen weitgehend überholt: Software entwickelt sich ständig weiter, Updates sind ständig verfügbar. Das heißt, dass heute auch ständig einzelne Programmbestandteile zusammengeführt und permanent auf deren Kompatibilität geprüft werden müssen.
Wird dieser Prozess rein linear gestaltet und die Komptabilität einzelner Softwarebestandteile erst ganz am Ende geprüft, können erhebliche Probleme auftreten. Für die Entwickler kann das zur “Integrationshölle” werden: Der Code für ein neues oder überarbeitetes Feature ist zwar fertiggestellt, aufgrund nicht-absehbarer Abhängigkeiten mit anderen Code-Bestandteilen läuft aber nichts wie geplant. Siehe dazu auch "Was ist Continuous Integration und was sind die Vorteile?".
Die Methode CI/CD möchte dafür Abhilfe schaffen. CI steht für “Continuous Integration”, einem Automatisierungsprozess für Entwickler. CD bedeutet sowohl “Continuous Delivery” (Codeänderungen werden automatisch getestet) als auch “Continuous Deployment” (Freigabeprozess von Codeänderungen beim Verfügbarmachen für die Endnutzer - also dem Deployment).
Continuous Integration
Codeänderungen einzelner Entwickler werden regelmäßig miteinander zusammengeführt. Das bietet daher vor allem den Vorteil, dass Inkompatibilitäten wesentlich früher aufgedeckt werden können.
Continuous Delivery & Continuous Deployment
Codeänderungen werden automatisierten Tests unterzogen und in Repositorys wie GitHub verfügbar gemacht. Dabei soll auch geprüft werden, wie sich der neue Code im Zusammenspiel mit bereits bestehendem Code auf dem Live-System verhält.
Mittlerweile gibt es spezifische Tools, die den CD-Prozess speziell für Software, die in einem Kubernetes-Cluster ausgeführt wird, verfügbar machen, Prüfungstools, die also explizit auf ein Kubernetes-Umfeld ausgelegt sind.
Das Tool Argo CD
Wir bei Blueshoe nutzen dafür das Tool Argo CD. Argo CD ist ein Kubernetes Controller der ständig eine laufende Applikation überwacht und den aktuellen Livestand eines Codes gegen einen gewünschten Stand abgleicht, wie er in einem Git-Repository definiert ist (hier kann auch der neue Softwarecode enthalten sein). Abweichungen kann Argo CD entweder automatisiert beheben oder visualisiert Abweichungen für Entwickler, damit diese schnell manuell behoben werden können
Technologien zum Geheimnismanagement
Geheimhaltung und Verschlüsselung von Daten
Bereits kleine Projekte benötigen für den Betrieb einige Daten, die geheim bleiben müssen und nur denjenigen Personen/Apps verfügbar sind, die sie auch wirklich brauchen. Dazu gehören unter anderem Passwörter für die Autorisierung bei anderen Services (Datenbank, API , etc.) oder Keys für die Verschlüsselung von gespeicherten Daten. Da diese nicht in falsche Hände gelangen sollten, dürfen sie nicht unverschlüsselt (plain-text) in die versionierten Kubernetes-Ressourcen (Kustomize-Manifeste, Helm-Charts, …) geschrieben werden. Es gibt verschiedene Tools, die das Management von solchen Geheimnissen ermöglichen und dabei unterschiedliche Ansätze verfolgen.
Welche Tools gibt es?
Secrets Plugin für Helm verschlüsselt Werte in den Helm-YAML-Dateien lokal mithilfe eines Keys (z.B. mit Mozilla SOPS), der nicht im Repo lebt und den Bearbeitern auf anderem Wege gegeben wird. Versioniert werden dann nur die verschlüsselten Geheimnisse. Bei der Anwendung der Charts entschlüsselt das Plugin diese Werte und bringt so die geheimen Daten in den Cluster.
Bitnami Sealed Secrets verfährt ähnlich, verschlüsselt die geheimen Daten allerdings im Cluster und generiert eigene Objekte, vom Typ SealedSecret, die versioniert werden können und die bei der Anwendung der Ressourcen dann von einem Operator entschlüsselt und in "echte" Kubernetes Secrets umgewandelt werden.
Andere Tools/Technologien, welche allein oder im Zusammenspiel mit den genannten Tools genutzt werden können, sind z.B. HashiCorp Vault,Azure Key Vault and AWS Secrets Manager.
3.8 Technologien für Monitoring, Logging und Metrics Collection
Um in einem System mit vielen Bestandteilen den Überblick zu behalten, ist es sinnvoll, Logs und andere Daten, die Aufschluss über den Zustand einzelner Komponenten geben, an einer zentralen Stelle zusammenfließen zu lassen und übersichtlich aufzubereiten. Tools, welche in diesem Kontext genutzt werden, sind z.B. Prometheus, Open Telemetry, Grafana, Logstash.

Cloud Native Development
Cloud Native Development beschreibt einen Software-Entwicklungsansatz, bei dem Applikationen von Anfang an für den Einsatz in der Cloud konzipiert werden (Ionos). Folglich ist es sinnvoll, auch die Entwicklung selbst schon so weit wie möglich in der späteren Cloud-Umgebung stattfinden zu lassen.
Mit unserem Blueshoe-eigenen Technologie-Stack bestehend aus Unikube, Gefyra und Getdeck haben wir wesentlich dazu beigetragen, diesen Prozess für ganze Entwicklerteams effizienter und effektiver zu gestalten.
Trotzdem möchten wir nicht verschweigen, dass es zu unseren eigenen Produkten auch einige nennenswerte Konkurrenten gibt, wie beispielsweise Okteto und Skaffold.
Trotzdem sind wir von unseren Produkten überzeugt: Sie bieten genau das, was Entwicklerteams benötigen, sind von uns umfangreich erprobt und finden immer weitere Wege in die Integration in andere Tools: Gefyra ist mittlerweile zu einer eigenen Docker Desktop Extension geworden.
Wenn du neugierig auf unsere Produkte geworden bist und mehr erfahren möchtest, kontaktiere uns!
Hier sind ein paar Artikel, die du auch interessant finden könntest:


ADRESSE
