
24.11.2022
Für die, die keinen Code schreiben aber mit Kubernetes arbeitenKubernetes für Anfänger: Der Cluster
Kubernetes ist derzeit "das ganz heiße Zeug". Auch für Entwickler ist es manchmal schwierig, Zugang zu dieser Technologie zu bekommen. Schwieriger ist es aber für Nicht-Entwickler. Was kann Kubernetes? Was unterscheidet die Anbieter? Welche Vorteile hat es?
Wir betrachten diese Fragen und geben einen Überblick über Kubernetes und verwandte Themen. Nicht bis ins kleinste Detail, aber so, dass auch Nicht-Entwickler verstehen, was Kubernetes ist.

Was ist Kubernetes
Kubernetes selbst ist keine Dienstleistung, die einzelne Anbieter anbieten. Vielmehr ist Kubernetes eine open-source Technologie, um Applikationen, die in Containern verpackt sind, zu managen und zu orchestrieren.
Theoretisch kann Kubernetes kostenlos auf GitHub heruntergeladen werden und wird dann auf lokalen Servern oder öffentlich (z.B. für einen Kunden) bereitgestellt.
Zusätzlich gibt es kostenpflichtige Angebote, die Kubernetes als open-source Technologie nutzen, aber darüber hinaus noch weitere Services zur Vereinfachung und Erweiterung von Kubernetes bereitstellen. Die bekanntesten Beispiele dafür sind Azure Kubernetes Service (AKS), Google Kubernetes Engine (GKE) oder Amazon Elastic Kubernetes Service (EKS). Die Nutzung dieser Services wird wahrscheinlich von den meisten Entwicklern genutzt werden.
Kubernetes ist in all diesen Angeboten weiterhin kostenlos, nicht aber die Cloud-Ressourcen oder Oberflächen, die die Anbieter bereitstellen. Die Kosten für die Verwaltung von EKS, AKS oder GKE sind oft gering, die Rechen- und Speicherkosten für Ressourcen, die die Dienste für Cloud-Ressourcen oder Oberflächen erheben, können sich aber schnell summieren.
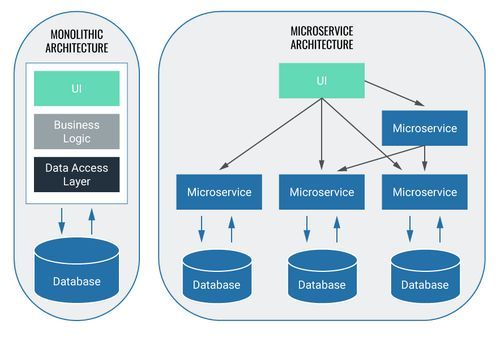
Back to the roots: Monolithen vs. Microservices
Sehr vereinfacht gesagt gibt es in der Software-Entwicklung 2 Ansätze, um Software zu entwickeln: den monolithischen Ansatz und den Bau von Microservices.
Bei Monolithen sind alle relevanten Bestandteile in einer Applikation enthalten. Bei Microservices gibt es für jeden Bestandteil dagegen jeweils eine eigenständige Applikation, die nur einen eng umrissenen Aufgabenteil bearbeitet. Benötigt ein Microservice zur Erledigung seiner Aufgaben Input eines anderen Microservice, kommunizieren die einzelnen Microservices via Schnittstellen untereinander. Ein Vorteil von Microservices gegenüber einer monolithischen Architektur ist, dass, sollte ein Microservice ausfallen, nicht zwangsläufig das ganze System nicht mehr einsatzbereit ist. Es gibt aber nicht das überlegene Verfahren. Blueshoe nutzt bei seiner Arbeit meist Microservices, da für unsere Zwecke hier die Vorteile überwiegen.
Zur Nutzung von Kubernetes ist es nicht notwendig, dass Microservices genutzt werden. Kubernetes kann auch zum Betreiben von Monolithen herangezogen werden.
Für die Nutzung von Kubernetes ist es aber unabdingbar, dass die Softwareanwendung in einen Container verpackt ist - und das geht mit Monolithen und Microservices.
Back to the roots: Container
Um auch Nicht-Entwicklern eine kurzen Einblick zu geben, warum Container genutzt werden, wollen wir ganz kurz und vereinfacht darauf eingehen.
Bei Software-Containern handelt es sich auch buchstäblich um Container. Sie bilden eine vordefinierte Umwelt, in der Code ausgeführt werden kann. Ein Container enthält also nicht nur Software, sondern bietet auch die Möglichkeit, die Umgebung, in der die Software ausgeführt wird (also den Container), vorzukonfigurieren. Bevor die Praxis der containerisierten Software aufgekommen ist, musste Software immer in unterschiedlichen Umgebungen ausgeführt werden, z.B. auf verschiedenen Computern. Es bestand also nicht nur die Herausforderung, dass die Software an sich fehlerfrei sein musste, sondern jede Umgebung musste auch gleich konfiguriert sein. Mit der Containerisierung von Software stellt der Container selbst die Umgebung dar, in der die Software ausgeführt wird. Der Container kann also auf unterschiedlichen Servern betrieben werden, ohne dass die einzelnen Server jeweils einzeln konfiguriert werden müssen.
Der bekannteste Anbieter, der das Verpacken von Software in Containern erlaubt, ist Docker. Daraus ergeben sich also “Docker Container.” “Container” wird also oft mit “Docker-Container” synonym verwendet. Für die Nutzung von Kubernetes ist es notwendig, dass Software in Container verpackt ist. Mit welcher Technik das herbeigeführt wird, ist nicht relevant.
Wie groß die einzelnen, in Container verpackten Applikationen dabei sind (siehe oben: monolithische Architektur vs. Microservices) ist ebenfalls nicht relevant - Kubernetes kann für beide Ansätze genutzt werden.
Die Software, die in einen Container verpackt wurde, wird an einem definierten Ort abgelegt. Das wird als Docker-Image bezeichnet. Wird die Software ausgeführt, wird immer auf dieses Image referenziert. Die Software kann also in mehreren Instanzen ausgeführt werden, wenn auf dasselbe Image referenziert wird.
Was Kubernetes genau macht
Die open-source Technologie Kubernetes erlaubt es, Container in einem definierten Umfeld zu verwalten. Dieses Umfeld muss sich von seiner Umgebung klar abgrenzen, also einen so genannten Cluster bilden und auf einem lokalen System oder z.B. einer öffentlichen Cloud (die für Kunden zugangsbeschränkt werden kann) hergestellt werden.
Ein Cluster ist ein Zusammenschluss von verschiedenen Teilelementen, die zur Ausführung der Kubernetes Technologie benötigt werden, zum Beispiel Nodes, Pods, etc. Eine Node entspricht dabei einem Server, der eine Softwareapplikation ausführt. Damit eine Node eine Softwareapplikation ausführen kann, muss die Software in einem Container verpackt sein und in der Node bereitgestellt werden (mehr dazu später).
“Server vs. Node” oder: “pet vs. cattle”
Ohne die Nutzung von Kubernetes wird Software direkt auf einem Server ausgeführt. Die Software ist dabei nur auf diesem einen Server verfügbar. Ist der Server nicht mehr erreichbar, kann auch die Software nicht mehr ausgeführt werden.
Neben der Pflege der eigentlichen Software ist bei dieser Lösung die Serverpflege essentiell. Der Server ist damit wie ein pet - ein Haustier. Er wird gehegt und gepflegt, es soll ihm gut gehen, er soll lange leben und nie krank werden. Alles, damit der Server die Software stabil ausliefern kann.
Demgegenüber ist eine Node ein anonymes Arbeitstier oder eine Drohne - also ein cattle. Nur eine Nummer, ohne Namen, ohne Gesicht. Stirbt ein Arbeitstier, wird es, ohne Aufsehen zu erregen, direkt durch ein anderes ausgetauscht. Viele Arbeitstiere bilden eine Herde anonymer Individuen. Analog dazu bilden mehrere Nodes einen Cluster.
Wird Software auf einem individuellen Server ausgeführt und der Server ist nicht mehr erreichbar, kann die Software auch nicht mehr ausgeführt werden, der Service ist für die User nicht mehr nutzbar. Ist die Node, auf der eine in Containern verpackte Applikation ausgeführt wird, nicht mehr erreichbar, kann der Container sehr schnell auf eine andere Node transferiert und damit die Software weiter ausgeführt werden.
Für die Verschiebung eines Containers in eine andere Node sorgt dabei Kubernetes “ganz von selbst”. Kubernetes ist im Beispiel also wie ein Aufseher, der dafür sorgt, dass immer ein Arbeitstier zur Verfügung steht, das die Applikation trägt. Kubernetes wird auch oft als ein Dienst bezeichnet, der Container orchestriert, indem er die Container wie ein Dirigent verfügbaren Nodes zuordnet.
Alternativen zu Kubernetes
Kubernetes ist nicht der einzige Dienst, um die Ausführung von Software in Container auf virtuellen Maschinen (den Nodes) zu orchestrieren. Neben Kubernetes gibt es noch eine ganze Reihe anderer Anbieter: Docker Swarm, Nomad oder Kontena seien hier als Alternativen genannt. Hier gibt es einen Überblick über die Vor- und Nachteile dieser und weiterer Applikationen im Vergleich zu Kubernetes. (Stand: 19.05.2022):
Warum Kubernetes nutzen?
Kubernetes bietet unbestreitbar viele Vorteile - aber gleichzeitig auch einige Nachteile. Ob Kubernetes genutzt werden soll oder nicht, will also gut überlegt sein.
Wir haben hier einige Argumente für und gegen Kubernetes zusammengetragen.

Jedem Vorteil von Kubernetes kann auch ein Nachteil zugeordnet werden. Eine einfache Antwort auf die Frage “Soll ich Kubernetes nutzen?” gibt es also nicht. Jede Antwort ist so individuell wie jede Software oder jeder Kunde von Blueshoe.
Wir bei Blueshoe haben uns aus folgenden Gründen entschieden Kubernetes als Erste-Wahl-Lösung zur Orchestrierung von Applikationen in Container zu nutzen:
- Die Projekte, die wir betreuen bringen meist so komplexe Applikationen hervor, das sich der Einsatz von Kubernetes lohnt
- Unsere Entwickler können nicht alle alternativen Produkte, die es zur Orchestrierung von containerisierter Software gibt, gleich gut beherrschen. Wir haben uns entschlossen, Kubernetes-Experten zu werden. Unser Wissen dabei können wir auf viele Projekte übertragen. Die Ramp-up-Phase für uns war hoch, aber wir profitieren nun davon
- Kubernetes wird von (fast) allen Cloud-Anbietern unterstützt - anders als alternative Systeme zur Orchestrierung von containerisierter Software. Damit sind unsere Kunden bei der Anbieterwahl nicht beschränkt.
Soll man Kubernetes selbst hosten oder einen managed Service in Anspruch nehmen?
Wie oben beschrieben handelt es sich bei Kubernetes um eine open-source Technologie, die Nutzung ist also grundsätzlich (lizenz)kostenfrei und kann vollkommen selbstständig gehostet werden. AKS, GKE, EKS oder andere Anbieter haben dazu gemanaged Services im Angebot, die die Nutzung von Kubernetes erleichtern sollen. Die Nutzung dieser Services ist das, was die Anbieter in Rechnung stellen.
Was also tun? Selbst hosten oder Geld für einen managed Service bezahlen?
Dabei sind zwei Faktoren zu berücksichtigen: Einerseits der Faktor, welche “Hardware” und welche Services die Anbieter bereitstellen. Diesen Aspekt haben wir in unserem Blogpost "Managed vs. Unmanaged Kubernetes" bereits zusammengestellt.
Andererseits darf nicht vergessen werden, dass auch die Personalkosten für die Verwaltung eines vollständig selbst-gehosten Kubernetesclusters nicht zu vernachlässigen sind. Hier wird anschaulich verdeutlicht, dass wenn ein Cluster 24/7 gewartet werden muss, zumindest 4 Vollzeit-beschäftigte Entwickler vorgehalten werden sollen um auch Urlaubs- und Krankheitszeiten kompensieren zu können. Es wird davon ausgegangen, dass bei der Nutzung eines gemanagten Services, der zwar auch durch einen Entwickler betreut wird, eine Vollzeitstelle genügt.
Zu bedenken ist außerdem, dass die Kostenstruktur für Nodes, Rechenleistungen, etc. bei den einzelnen Anbietern zum Teil sehr undurchsichtig ist. Welche Kosten hier genau auf einen zukommen hängt wesentlich vom Umfang der zu verarbeitenden Informationen und der dafür notwendigen Rechenleistung ab. Die Kosten sind oft so dargestellt, dass es für Personen, die nicht mit der technischen Entwicklung und/oder Umsetzung von Software (z.B. Fachabteilungen) vertraut sind, kaum zu beurteilen ist, wie hoch die notwendigen Kapazitäten sind und welche Kosten anfallen werden. So können die Kosten beispielsweise je nach spontanem Nutzeraufkommen sehr stark variieren, da dadurch wesentlich mehr Rechenkapazität benötigt wird. Eine grobe Kostenschätzung für einen managed Service sollte auch immer mit einem inhaltlich involvierten Entwickler vorgenommen und nicht zu knapp kalkuliert werden.
Was man zum Bau von Kubernetes braucht
Im zweiten Teil wollen wir nun zu Kubernetes selbst kommen. Dabei sollen Begrifflichkeiten geklärt und aufgezeigt werden, wie diese im Einzelnen zusammenhängen.
Hier findet sich ein guter erster Überblick sowohl für Nicht-Entwickler als auch für Entwickler, die sich zum ersten Mal mit Kubernetes befassen. Wir greifen im Folgenden hauptsächlich auf diese Quelle zurück.
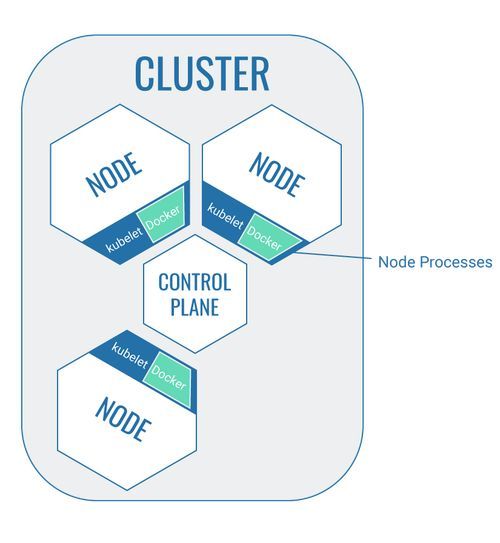
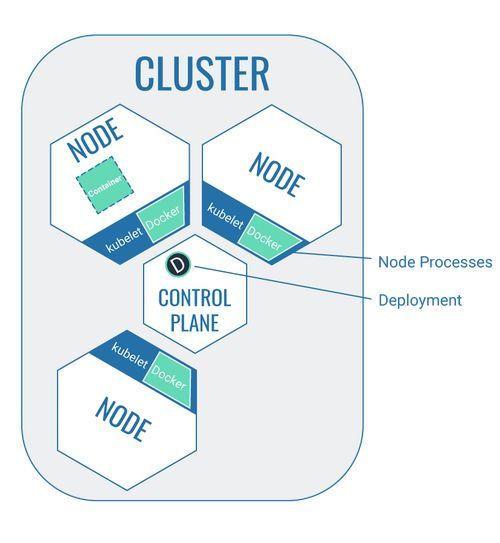
Cluster
Kubernetes kann nur in einem definierten Umfeld verwendet werden. Der Cluster selbst kann nicht mit Kubernetes gleichgestellt werden. Kubernetes bietet als Technologie aber die Möglichkeit, einen Cluster zu erstellen, der verschiedene Bestandteile gegen seine Umgebung abgrenzt.
Im Kontext von Kubernetes ist ein Cluster also ein Zusammenschluss von verschiedenen Bestandteilen, die für die Nutzung von Kubernetes benötigt werden, der klar von der Umwelt abgegrenzt ist. Neue Bestandteile (z.B. neue Nodes) müssen dem Cluster explizit durch einen Entwickler zugeordnet werden und können nicht automatisch in den Cluster gelangen.
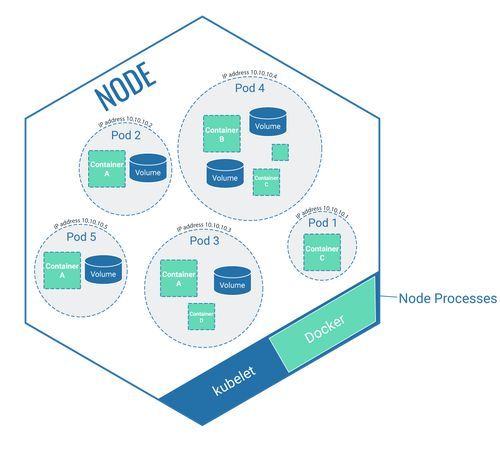
Node
Eine Node ist eine virtuelle Maschine oder ein physischer Computer. Eine Node ist der Bestandteil des Clusters, der die in Container verpackte Software ausführt. Die containerisierte Software selbst wird über Pods auf die Node gebracht.
Die Node selbst besitzt kleinere Applikationen um diese Arbeit auch durchführen zu können:
- Kubelet: Jede Node besitzt ein sogenanntes Kubelet, der die Node selbst managt und via API mit dem Control Plane kommuniziert
- Tools um die Container innerhalb der Node zu betreiben: Die Node stellt Platz zur Verfügung, um die containerisierte Software zu beherbergen. Allerdings kann es notwendig werden, dass Arbeiten an der containerisierten Software durchgeführt werden. Um die Software auf der Node bearbeiten zu können (z.B. zu starten) verfügt die Node über Tools, um die Software, die im Container auf der Node liegt, ansprechen zu können. In der Darstellung werden Docker-Container genutzt. Aus diesem Grund handelt es sich um ein spezielles Tool, um Docker-Container zu verwalten.
Zusätzlich können Nodes Pods umfassen, die wiederum containerisierte Software beinhalten. Dazu aber später mehr.
Control Plane
Der Control Plane ist das Herzstück von Kubernetes, die ausführende Kubernetes-Instanz (sozusagen die Schaltzentrale), die alle Aktivitäten im Cluster koordiniert. Ein Control Plane ist ebenfalls eine Node, allerdings mit der speziellen Aufgabe, den Cluster zu koordinieren.
Der Control Plane stellt eine API zur Verfügung, um mit den anderen Clusterbestandteilen zu kommunizieren.
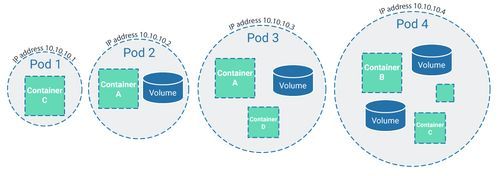
Pods
Der Begriff “Pod” gehört bestimmt zu denjenigen, die im Kubernetes-Umfeld am meisten Verwendung finden. Pods haben nichts mit Star Wars zu tun, sondern sind die kleinsten Einheiten im Kubernetes-Universum.
Pods als kleinste eigenständige Einheiten im Cluster fassen mehrere Elemente sinnhaft zusammen, die im Deployment-Prozess in den Cluster gebracht werden. Pods sind also “Hülsen” und können beispielsweise folgende Elemente umschließen:
- geteilte Speichereinheiten, z.B. Volumes
- cluster-spezifische IP-Adressen
- Informationen darüber, wie Container betrieben werden, z.B. Image-Versionen der Applikation, Informationen zu Ports, etc.
Jeder Pod verfügt dabei über eine eigene IP-Adresse, die nur innerhalb des Clusters bekannt ist. Das heißt, die einzelnen Pods können nur im Cluster angesprochen und nicht von außen gesteuert werden.
Eine Node kann mehrere Pods beherbergen. Jeder Pod ist immer nur einer Node zugeordnet und verbleibt bei dieser Node bis sie gelöscht wird oder aufgrund anderer Fehler “stirbt”. Passiert das,”stirbt” auch der Pod. Wenn das passiert, kann durch den Deployment-Prozess (siehe unten) der Pod auf einer anderen Node aber neu erzeugt werden und somit “ewig leben”.
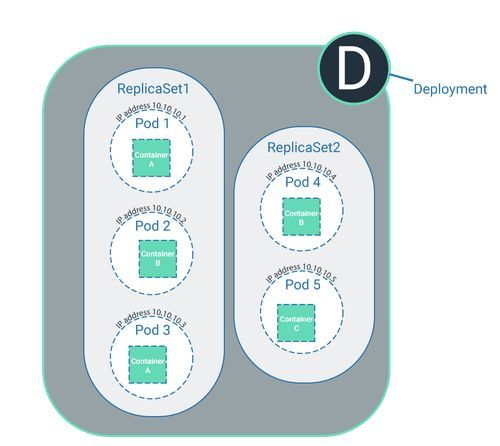
Replica-Sets und der Deployment-Prozess
Mit Node, Control Plane und Pods haben wir jetzt die einzelnen Bestandteile des Cluster besprochen. Aber wie agieren die einzelnen Bestandteile miteinander und wie tragen sie dazu bei, dass von Entwicklern geschriebener Code korrekt ausgeführt wird?
Dafür ist der Deployment-Prozess zuständig. Erst mit dem Deployment bringen Entwickler den Code in den Cluster. Im Deployment-Prozess wird beschrieben, wie oft einzelne Softwarebestandteile im Cluster ausgeführt werden sollen.
Hier wird beispielsweise beschrieben, welche Software ausgeführt werden soll. Die Software ist in ein Container-Image verpackt und das Image ist an einer definierten Stelle abgelegt (siehe oben). Wird im Deployment beschrieben, dass die Software einmalig ausgeführt werden soll, ist die Anzahl des Replica-Sets = 1 und es wird dafür ein Pod etabliert. Soll die Software öfters ausgeführt werden, ist die Anzahl des Replica-Sets beispielsweise =3. Im Replica-Set werden nun 3 Pods etabliert, die jeweils auf dasselbe Container-Image referenzieren.
Ist das Replica-Set = 3 und umfasst somit 3 Pods, können diese 3 Pods auf derselben Node ausgeführt werden. Alle drei Pods führen über die Referenz zum Container-Image mit demselben Code dann zwar dieselbe Software aus, es handelt sich aber um unterschiedliche Pods. Somit bleibt die oben beschriebene Prämisse bestehen, dass jeder Pod nur einmalig im Cluster enthalten sein kann und immer nur einer Node zugeordnet ist.
Ein Deployment kann mehrere Replica-Sets umfassen, die auf unterschiedliche oder auch dieselbe Software referenzieren.
Wie zuvor beschrieben bietet der Deployment-Prozess den Vorteil, dass, sollte eine Node z.B. gelöscht werden oder fehlerhaft sein, der Pod mit der beinhalteten Software auf einer anderen Node erneut erstellt werden kann. Die Information, wie ein Pod im Cluster ausgeführt werden soll, ist im Deployment beschrieben. Durchgeführt wird der Schritt, den Pod einer Node zuzuordnen durch einen Service (siehe unten).
Um das Deployment zu starten und zu managen, wird bei Kubernetes das Command-Line-Interface genutzt - das Kubectl. Kubectl ist für Nicht-Entwickler aber weniger relevant, die Bezeichnung sollte aber an dieser Stelle einmal erwähnt werden.
Service, Label und Selector
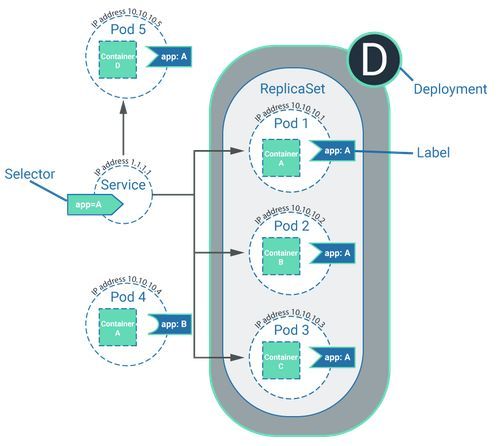
Ein Service in Kubernetes hat nichts mit einem “managed Kubernetes-Service” (siehe oben) zu tun, sondern ist ein Bestandteil im Cluster. Ein Service kann als eine Abstraktion verstanden werden, die Pods logisch zusammenfasst und definiert, wie die Pods miteinander interagieren können. Dabei interagieren die Pods nicht direkt miteinander. Vielmehr können den Pods Labels zugeordnet werden. Der Service verfügt dabei über den komplementären Selector. Über die Labels am Pod und die Selektoren am Service können Pods miteinander interagieren.
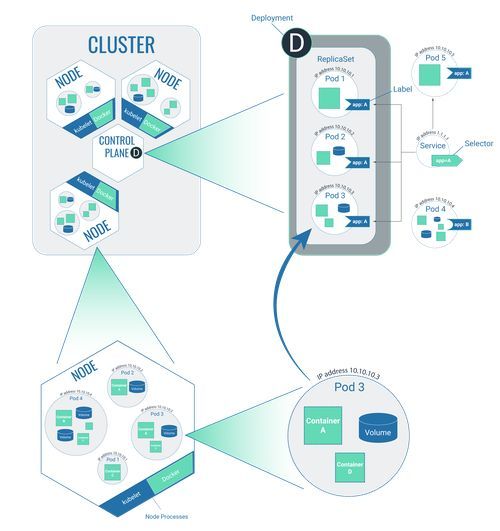
Der Cluster im Überblick
Zusammengefasst besteht ein Cluster aus mehreren Nodes, wovon eine Node den Control Plane darstellt.
Die Software, die im Cluster ausgeführt werden soll, ist in einen Container verpackt und als Container-Image an einem definierten Ort festgelegt. Im Cluster selbst wird also nicht die Software selbst abgelegt, sondern immer nur auf das Container-Image referenziert.
Im Deployment-Prozess wird beschrieben, welche Software in welcher Form (z.B. wie oft) ausgeführt werden soll. Dafür werden ein oder mehrere Replica-Sets angelegt. Der Deployment-Prozess ist auf dem Control Plane abgelegt.
Nach dem Deployment werden die im Deployment-Prozess definierten Pods im Cluster angelegt und auf die verschiedenen Nodes verteilt.
Services im Cluster verfügen über Selektoren, Pods können über die komplementären Labels zu den Selektoren verfügen. Durch dieses Schlüssel-/Schloss-Prinzip ist es möglich, dass die Pods miteinander in Interaktion stehen. Nur wenn ein Pod über ein Label verfügt, kann er mit anderen Pods interagieren, ansonsten steht der Pod für sich alleine.
Clustergröße
Der Vorteil von Kubernetes ist, dass das System erkennen kann, wann eine Node (= virtuelle Maschine) nicht mehr betriebsbereit ist. Anstatt dass die Software dann nicht mehr ausgeführt werden könnte (wie das der Fall wäre, würde die Software auf einem einzelnen Server ausgeführt werden), kann Kubernetes die Software im Container automatisiert einer anderen funktionsfähigen Node zuordnen. Aus diesem Grund sollte ein Cluster im Produktivsystem aus mind. 3 Nodes bestehen: Davon ist eine Node der notwendige Control plane, die anderen beiden Nodes beherbergen die auszuführende Software in Pods. Ein Pod läuft dabei nur auf einer Node, die verbleibende Node steht dann “nur” für den Fall bereit, dass die andere ausfällt.
Zusammenfassung
Kubernetes selbst ist eine open-source-Software, die von jedem kostenfrei genutzt werden kann. Es handelt sich dabei um einen Dienst, der Software ausführt und gegenüber dem Betrieb von eigenständigen Servern eine ganze Reihe Vorteile bietet.
Anbieter wie AKS, GKE oder EKS stellen darüber hinaus weitere Services in Zusammenhang mit Kubernetes bereit, die die Administration erleichtern sollen. Für diese Services fallen aber eine ganze Reihe von Kosten an, die nicht leicht zu überblicken sind.
Kubernetes bezeichnet eine Technologie, die eine Reihe einzelner Komponenten umfasst. Erst im Zusammenspiel von Nodes, Pods und dem Controle Plane kann ein Cluster erstellt werden, der zum Betrieb von Kubernetes notwendig ist.
Kubernetes ist kein Allheilmittel, das für jede Software gleichermaßen geeignet ist. Ob Kubernetes für den Betrieb einer speziellen Software oder für eine Organisation als ganze geeignet ist und ob die Services von AKS, GKE, EKS oder anderen hinzugekauft werden sollen, muss im Einzelfall beurteilt werden.
Wir hoffen, wir konnten euch einen guten Überblick geben, was Kubernetes ist, wie es sich von anderen Technologien zum Ausführen von Software unterscheidet und dass ein Pod in der Kubernetes-Welt nichts mit Podrennen in Star Wars Filmen zu tun hat.
Hast du noch Fragen oder eine Meinung? Mit deinem GitHub Account kannst Du es uns wissen lassen...
Hier sind ein paar Artikel, die du auch interessant finden könntest:

Strongswan-VPN in Kubernetes: Externe Dienste sicher einbinden
In manchen Fällen benötigt es eine VPN-Anbindung zu einem externen Service - was mit Kubernetes tricky sein kann. In diesem Beitrag zeigen wir, wie man mit StrongSwan einen IPsec-Tunnel aus Kubernetes heraus zu einem externen Dienst aufbaut und dabei Nginx als Reverse-Proxy nutzt. Das Setup ist klar strukturiert, gut wartbar und unterscheidet dynamisch zwischen Staging und Production.

Kubernetes Backup in Storage Buckets
Wir nutzen neben Kubernetes auch Cloud Storage, Cloud SQL und GitHub Actions, um unsere Anwendungen effizient zu betreiben – und zu sichern. In diesem Artikel zeigen wir dir, wie du eine zuverlässige Kubernetes Backup Strategie umsetzt, um Datenbanken, Medien und Code vor Verlust zu schützen.

Gefyra Roadmap 2025
Gefyra plant Großes für 2025! Von verbesserten Developer-Tools über neue Integrationen bis hin zu mehr Performance – die Roadmap verspricht spannende Neuerungen. In diesem Blogpost werfen wir einen Blick auf die kommenden Features und zeigen, wie Gefyra die Entwicklung und das Debugging in Kubernetes weiter revolutionieren will. Bleib dran für einen Ausblick auf das nächste Kapitel!

Kostenoptimierung eines Azure Kubernetes Clusters
Cloud-Ressourcen sind mächtig und praktisch, aber teuer – besonders Kubernetes-Cluster. In diesem Blogpost zeigen wir, wie wir in einem Bestandsprojekt die Azure Kubernetes Service Kostenoptimierung erfolgreich umgesetzt haben. Dabei stellen wir Strategien, Tools und Best Practices vor, die geholfen haben, AKS Kosten zu reduzieren, ohne die Performance zu beeinträchtigen.

Elasticsearch: Die leistungsstarke Suchlösung für deine Daten.
Elasticsearch ist eine Open-Source-Such- und Analyse-Engine, die auf Apache Lucene basiert. Sie ermöglicht es, große Mengen an Daten in Echtzeit zu durchsuchen und zu analysieren. In diesem Artikel werfen wir einen genaueren Blick auf Elasticsearch, erkunden seine wichtigsten Funktionen und zeigen dir anhand von Praxisbeispielen, wie du Elasticsearch in dein Projekt integrieren kannst.

Effiziente Betriebszeiten mit KEDA: Dynamisches Autoscaling für Kubernetes-Cluster
Kubernetes ist leistungsstark, doch ohne optimierte Betriebszeiten können unnötige Ressourcen und Kosten entstehen. KEDA (Kubernetes Event - Driven Autoscaling) ermöglicht es, Workloads dynamisch zu skalieren und z.B. außerhalb definierter Betriebszeiten zu pausieren. In diesem Blogpost zeigen wir, wie du mit KEDA deinen Cluster an Arbeitszeiten anpasst – für mehr Effizienz und reduzierte Hosting-Kosten.
Was unsere Kunden über uns sagen






- Ofa Bamberg GmbHB2B Online-Shop | B2C Website | Hosting | Betreuung | Security© Ofa Bamberg GmbH
- Ludwig-Maximilians-Universität MünchenPlattformentwicklung | Hosting | Betreuung | APIs | Website
Blueshoe hat unsere Forschungsdatenplattform Munich Media Monitoring (M3) entwickelt und uns hervorragend dabei beraten. Das Team hat unsere Anforderungen genau verstanden und sich aktiv in die Ausgestaltung der Software und der Betriebsumgebung eingebracht. Wir sind froh, dass auch Wartung und weiterführender Support in Blueshoes Händen liegen.
- Deutsches MuseumDigitalisierung | Beratung | Datenbank-Optimierung | GraphQL | CMSFoto: Anne Göttlicher
Im Rahmen eines komplexen Digitalisierungsprojekts für unsere Exponate-Datenbank war Blueshoe ein äußerst verlässlicher Partner. Sie haben uns nicht nur während des gesamten Projekts hervorragend beraten, sondern unsere Anforderungen perfekt umgesetzt. Dank ihrer Arbeit ist unsere Datenbank nun ein bedeutender Mehrwert für die weltweite wissenschaftliche Forschung.
- Fonds Finanz Maklerservice GmbHPlattformentwicklung | Prozess-Systeme | Hosting | Betreuung | Zertifikate | Website© Fonds Finanz Maklerservice GmbH
Blueshoe ist unsere verlängerte Werkbank für Entwicklung, Wartung und Support unserer Weiterbildungs- und Zertifizierungsplattformen. Das Team hat sich gründlich in unsere Abläufe eingearbeitet, und wir freuen uns, Blueshoe als zuverlässigen Partner an unserer Seite zu haben.
- Technische Universität HamburgPlattformentwicklung | Beratung | Prozess-Systeme | Hosting | Website
Seit 2019 unterstützt uns die Blueshoe GmbH tatkräftig bei der Entwicklung und Weiterentwicklung des "Digital Learning Lab" und der "Digital Learning Tools". Dank ihrer Beratung konnten wir von Anfang an auf eine zukunftssichere, moderne technische Struktur setzen. Die Zusammenarbeit ist reibungslos, und wir fühlen uns rundum gut betreut. Und davon profitieren dann auch die Lehrkräfte in Hamburg.




