

30.07.2020
So viel wie nötig, so wenig wie möglichStrategien für schlanke Docker Images
Docker ist in den letzten Jahren immer populärer geworden und hat sich mittlerweile praktisch zum Industriestandard für Containerisierung gemausert, sei es nun mittels docker-compose oder auch mit Kubernetes. Oftmals wird Docker auch gleich als Synonym für Container verwendet. Dabei gibt es einige Aspekte, auf die man beim Erstellen von Dockerfiles achten sollte. In diesem Blogpost zeigen wir euch ein paar Strategien, um möglichst schlanke Docker Images zu erzeugen.

WARUM BESCHÄFTIGEN WIR UNS MIT DOCKER IMAGES?
Docker Images haben sich auch bei Blueshoe als präferierte Technologie herausgestellt, um einerseits Anwendungen lokal zu entwickeln, und, um andererseits die Anwendungen in einem Testing-/Staging- oder Produktiv-System zu betreiben (“Deployment”). Neben der ungewohnten Situation als Python-Entwickler plötzlich wieder eine gewisse Build-Wartezeit zu haben, sind uns mit als erstes die zum Teil großen resultierenden Docker Images aufgefallen.
GRÖSSE DER DOCKER IMAGES MINIMIEREN
Gerade das Minimieren der Imagegröße spielt für uns eine zentrale Rolle für die Erstellung unserer Dockerfiles. Das Docker Image sollte natürlich über alles Benötigte verfügen, um die Anwendung ausführen zu können - aber eben auch nicht mehr. Überflüssiges sind z. B. Software-Pakete und Libraries, die nur zum Kompilieren oder für das Ausführen automatisierter Tests benötigt werden.
Man kann gleich mehrere Gründe finden, wieso in einem Docker Image nur das absolut Nötigste vorhanden sein sollte:
- Zum einen wird die Sicherheit des Images erhöht. Um eine simple Django-Anwendung auszuführen, benötige ich sicherlich kein ausgewachsenes Debian- oder Ubuntu-Image. Es genügt ein einfaches Python-Image als Basis, das praktisch kaum mehr können muss als mittels eines Python-Interpreters bzw. Application Server die Django-Anwendung auszuführen. Warum wird dadurch nun die Sicherheit erhöht? Ganz einfach, weniger Libraries reduzieren die Anzahl der Angriffsflächen. Der hier verlinkte Artikel ist zwar bereits ein Jahr alt, erläutert aber aufschlussreich die zugrunde liegende Problematik und stellt dar, wie man mit kleineren Versionen des Basis-Images bekannte CVEs (Common Vulnerabilities and Exposures) reduzieren kann.
- Ein weiterer Aspekt ist die Geschwindigkeit. Im Betrieb kann es oberflächlich betrachtet eigentlich egal sein, ob das Docker Image nun zwei Gigabyte oder nur 200 Megabyte groß ist. Das Deployment ist oftmals automatisiert und ob es nun ein paar Minuten länger dauert, bis der (neue) Code bereitsteht, spielt i. d. R. auch keine große Rolle. Aber hier gilt natürlich: Was wir an unnötigem Datenverbrauch und überflüssigen Datenübertragungen einsparen können, sollten wir einsparen.
- Als Entwickler kann ich hauptsächlich von kleinen Docker Images profitieren, wenn ich keine automatisierte Build-Pipeline habe, sondern die Images selbst baue und z. B. in einer Container Registry (der zentrale Speicher für Images) bereitstelle. Habe ich nun ein Dockerfile erzeugt, das zwei Gigabyte groß ist, und sitze Corona-bedingt im Home Office bei nicht ganz so optimaler Internetverbindung, kann der Upload durchaus eine gewisse Zeit dauern. Ärgerlich ist es allemal, wenn der Entwicklungsprozess unnötig in die Länge gezogen wird und sei es auch nur für eine halbe Minute bei jedem Build.
- Der nächste Aspekt ist der Ressourcenverbrauch. Nicht nur auf meinem Laptop, der mit der Zeit durch immer mehr Docker Images zugemüllt wird, die ich regelmäßig aufräumen muss, sondern auch in der Container Registry. Diese könnte z. B. von Gitlab gehostet sein. Klar ist Speicherplatz i. d. R. kein sonderlich großer Kostenfaktor, wenn allerdings jedes Docker Image ein bis zwei Gigabyte groß wird, und Woche für Woche dutzende Images in die Registry gepusht werden, kann sich der angesammelte Speicherplatz durchaus auf eine respektable Menge summieren. Wenn wir es schaffen, die Docker Images auf die Hälfte oder ein Viertel ihrer Größe zu reduzieren, haben wir schon einiges gewonnen.
- Zu guter Letzt ist natürlich auch die Umwelt zu nennen. Jedes Docker Image wird zunächst mal in eine Registry gepusht und von dort wieder heruntergeladen. Sei es nun auf den Laptop eines Entwicklers, oder von einem Produktiv-System. Wenn meine Docker Images unnötigerweise viermal so groß sind, wie sie sein müssten, sorge ich dafür, dass permanent viermal so viel Traffic durch die Verwendung meiner Images entsteht oder zusätzliche Speichersysteme betrieben werden müssen.

WELCHE ANFORDERUNGEN BESTEHEN FÜR EIN DOCKER IMAGE?
Trotz aller Minimierung der Imagegröße müssen natürlich auch einige Anforderungen bedacht werden. Wenn ich meine Docker Images bis aufs letzte Megabyte optimiere, danach aber nicht mehr vernünftig damit entwickeln kann, oder die Anwendung nicht robust läuft, ist nicht viel gewonnen. Im Endeffekt kann man die Überlegungen auf die drei Ebenen Entwicklung, Testing/Staging und Production herunterbrechen.
Als Entwickler möchte ich möglichst wenig in meinem Arbeitsfluss gestört werden, mein Komfort steht hier definitiv im Vordergrund. Das heißt, ich benötige ein Docker Image, das im Idealfall eine möglichst geringe Build-Zeit hat und das z. B. live code-reloading unterstützt. Außerdem möchte ich vielleicht noch weitere Tools wie den Python Remote Debugger oder auch Telepresence einsetzen. Evtl. benötige ich dafür weitere Dependencies, die z. B. in einem Produktiv-System nicht relevant sind.
Für Testing-, bzw. Staging- und für Produktiv-Systeme sehen die Anforderungen sehr ähnlich aus. Hier steht ganz klar die Sicherheit an erster Stelle. Ich möchte möglichst wenig Libraries und Packages auf dem System haben, die für die Ausführung der Anwendung gar nicht gebraucht werden. Eigentlich sollte ich als Entwickler gar keinen Bedarf mehr haben, mit dem laufenden Container zu interagieren, wodurch hier sämtliche Bedenken bzgl. Komfort vernachlässigt werden können.
Aber gerade auf einem Testing-/Staging-System kann es dennoch sehr praktisch sein, wenn ich dort zu Debugging-Zwecken gewisse Packages verfügbar habe. Das ist allerdings nicht unbedingt ein Argument dafür, diese Packages bereits im Docker Image für den Fall der Fälle bereitzuhalten. Mittels Telepresence lässt sich ja z. B. in einer Kubernetes-Umgebung ein Deployment austauschen. Das bedeutet, ich kann mir lokal ein Docker Image bauen, das all meine benötigten Dependencies bereitstellt, und dieses in meinem Testing-/Staging-Cluster ausführen. Wie man das bewerkstelligen kann, haben wir in einem unserer letzten Blogposts - Cloud Native Kubernetes development - dargestellt.
Gerade zu Beginn der Entwicklungsphase eines Projekts kann der oben beschriebene Use-Case recht häufig auftreten. Für ein Produktiv-System sollte das aber eigentlich keine Rolle mehr spielen. Dort möchte ich vielleicht noch Logs betrachten, was einerseits mittels kubectl bewerkstelligt werden kann oder evtl. auch mit einer Log-Collector-Lösung. Im Endeffekt möchte ich, dass das Testing-/Staging-System mit dem identischen Docker Image ausgeführt wird, wie das Produktiv-System. Ansonsten besteht z. B. die Gefahr, dass im Produktiv-System ein Fehlverhalten auftritt, welches im Testing-/Staging-System aufgrund der unterschiedlichen Umgebung nicht aufgetreten ist.
Auch von Operations-Seite können Anforderungen kommen, z. B. in Form eines Vulnerability-Checks, um zu gewährleisten, dass bekannte Vulnerabilities, wo es möglich ist, gar nicht erst im Image vorhanden sind, bzw. damit behebbare Vulnerabilities auch behoben sind. Weiterhin kann auch eine Company-Policy Einfluss auf das Dockerfile haben, entweder die der eigenen Firma oder die des Auftraggebers. Ein Szenario wäre z. B. der Ausschluss bestimmter Basis Images oder das Gewährleisten der Verfügbarkeit gewisser Packages oder Libraries.
EVOLUTION EINES DOCKER IMAGES
In den folgenden Abschnitten wollen wir nun betrachten, welche Schritte man konkret vornehmen kann, um das eigene Dockerfile zu optimieren. Zunächst schauen wir uns Voraussetzungen an, die das resultierende Docker Image beeinflussen können. Außerdem werfen wir einen Blick auf die Strategien und Patterns für Dockerfiles, bevor wir uns in mehreren Iterationen die Auswirkungen der Optimierungen anschauen.
VORAUSSETZUNGEN
An erster Stelle steht die Auswahl des Basis Images. Dieses muss auch im Dockerfile an erster Stelle definiert werden. Für eine Django-Anwendung genügt uns ein Python Base Image. Wir könnten zwar natürlich auch einfach ein Ubuntu Image wählen, aber wir wollen die Image-Größe ja möglichst klein halten und redundante Packages gar nicht erst im Image haben. Der Docker Hub stellt viele vorgefertigte Images bereit. Auch für Python gibt es verschiedene Images, die anhand der Python Versionsnummer oder auch mit den Begriffen slim und alpine unterschieden werden.
Das “Standard” Python Base Image basiert auf Debian Buster und stellt somit die größte der drei Varianten dar. Die slim Variante basiert ebenfalls auf Debian Buster, allerdings mit herunter getrimmten Packages. Das resultierende Image ist somit natürlich kleiner. Die dritte Variante ist alpine und basiert, wie der Name vermuten lässt, auf Alpine Linux. Das entsprechende Python Base Image hat die geringste Größe, allerdings kann es gut sein, dass man benötigte Packages im Dockerfile nachinstallieren muss.
Einen u. U. großen Einfluss auf das Dockerfile haben auch die System Runtime und Build Dependencies. Gerade beim Base Image gilt zu beachten, dass ein auf Alpine basierendes Image mit musl libc ausgeliefert wird und nicht mit glibc, wie auf Debian-basierten Base Images. Selbiges gilt für gcc, der GNU Compiler Collection, die nicht standardmäßig auf Alpine verfügbar ist.
Als Django-Entwicklung haben Anwendungen natürlich einige pip-Requirements. Je nach gewähltem Basis-Image muss das Dockerfile also sicherstellen, dass alle für die pip-Requirements benötigten System-Packages und Libraries installiert sind. Aber auch die pip-Requirements selbst können Auswirkungen auf das Dockerfile haben, wenn ich zusätzliche Packages für die Entwicklung habe, die jedoch im Produktiv-Betrieb nicht benötigt werden und dort auch nicht vorhanden sein sollen. Ein Beispiel dafür ist das pydevd-pycharm Package, welches wir lediglich für den Python Remote Debugger in PyCharm benötigen.
STRATEGIEN UND PATTERNS FÜR DOCKERFILES
Mit der Zeit haben sich verschiedene Strategien und Patterns entwickelt, um Dockerfiles zu gestalten und zu optimieren. Die Herausforderung, eine kleine Image-Größe zu erhalten, knüpft sich stark daran, wie aus dem Dockerfile ein Image wird. Jede Instruktion fügt einen neuen Layer hinzu, wobei jeder Layer auf dem vorherigen aufbaut. Mit diesem Wissen ist es natürlich naheliegend zu versuchen, die Anzahl der Layer und die Größe der verschiedenen Layer möglichst gering zu halten. Man kann z. B. nicht mehr benötigte Artefakte innerhalb eines Layers löschen, oder mit verschiedenen Shell Tricks und anderen Logiken verschiedene Instruktionen in einem Layer zusammenfassen.
Ein mittlerweile veraltetes Pattern ist das sogenannte Builder Pattern. Hierfür erstellt man ein Dockerfile für die Entwicklung, das Builder-Dockerfile. Dieses enthält alles benötigte, um die Applikation zu bauen. Für die Testing-/Staging- und Produktiv-Umgebungen erstellt man ein zweites, herunter getrimmtes Dockerfile. Dieses enthält die Anwendung an sich und ansonsten nur das Nötigste, um die Software auszuführen. Dieser Ansatz ist zwar machbar, hat allerdings zwei große Nachteile: Zum einen ist es definitiv nicht ideal zwei verschiedene Dockerfiles warten zu müssen, zum anderen entsteht dadurch ein komplizierter Workflow:
- Builder Image kompilieren
- Container anhand Builder Image erstellen
- benötigte Artefakte aus Container kopieren bzw. extrahieren
- Container löschen
- Production Image anhand der extrahierten Artefakte builden
Dieser Ablauf lässt sich natürlich durch Scripts automatisieren, ist aber dennoch nicht ideal.
Als bessere Lösung finden mittlerweile sogenannte Multi-Stage Dockerfiles immer mehr Verbreitung. Diese werden von Docker selbst empfohlen. Ein Multi-Stage Dockerfile folgt einer eigentlich recht simplen Struktur:
Die verschiedenen Stages werden durch FROM-Statements voneinander getrennt. Dabei kann eine “Stage” auch immer mit einem Namen versehen werden, was es einfacher macht, diese Stage zu referenzieren. Da jede Stage mit einem FROM-Statement beginnt, wird auch in jeder Stage ein neues Base-Image verwendet. Der Vorteil mehrere Stages ist nun, dass sich einzelne Artefakte aus einer Stage selektiv in eine nächste kopieren lassen. Es ist auch möglich an einer gewissen Stage zu stoppen, um z. B. Debugging-Funktionalitäten bereitzustellen, also um verschiedene Stages für Development/Debug und Staging/Production zu unterstützen.
Wird während des Build-Prozesses keine Stage angegeben, an der gestoppt werden soll, wird das komplette Dockerfile durchlaufen, was im Docker Image für das Produktiv-System resultieren sollte. Im Vergleich zum Builder Pattern wird dabei nur ein Dockerfile benötigt und es ist kein Build-Script nötig, um den Workflow abzubilden.
EVALUATION VERSCHIEDENER DOCKERFILES
Mit all diesem Wissen machen wir uns nun an die Evaluation verschiedener Dockerfiles. Wir haben sechs verschiedene Dockerfiles geschrieben, die wir anhand der Größe evaluiert haben. Zunächst schauen wir uns nun der Reihe nach die Dockerfiles mit den gewählten Optimierungen an. Allen Dockerfiles ist gemeinsam, dass postgresql-client bzw. postgresql-dev installiert wird, das Kopieren und Installieren von pip-Requirements sowie das Kopieren der Anwendung.
DOCKERFILE 1 - NAIVE
FROM python:3.8
RUN apt-get update
RUN apt-get install -y --no-install-recommends postgresql-client
COPY requirements.txt /requirements.txt
RUN pip install -r /requirements.txt
COPY src /app
WORKDIR /app
Das erste Dockerfile basiert auf dem python:3.8 Basis Image. Wir bekommen also alle Debian “Nuts and Bolts” mitgeliefert, um innerhalb des Containers praktisch ohne Einschränkungen arbeiten zu können.
DOCKERFILE 2 - NAIVE, LÖSCHEN DER APT-LISTS
FROM python:3.8
RUN apt-get update \
&& apt-get install -y --no-install-recommends postgresql-client \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt /requirements.txt
RUN pip install -r /requirements.txt
COPY src /app
WORKDIR /app
Dieses Dockerfile ist identisch zum ersten, mit der Ausnahme, dass nach der Installation der benötigten zusätzlichen Packages der Inhalt des Verzeichnisses /var/lib/apt/lists/ gelöscht wird. In diesem Verzeichnis werden nach einem apt update Paketlisten gespeichert, die für unser Docker Image nicht mehr relevant sind.
DOCKERFILE 3 - ALPINE NAIVE
FROM python:3.8-alpine
RUN apk update && apk --no-cache add libpq gcc python3-dev musl-dev linux-headers postgresql-dev
COPY requirements.txt /requirements.txt
RUN pip install -r /requirements.txt
COPY src /app
WORKDIR /app
Unser drittes Dockerfile basiert ganz simpel auf Alpine Linux. Da in Alpine einige Packages für den Betrieb der Anwendung fehlen, müssen diese zunächst noch installiert werden.
DOCKERFILE 4 - ALPINE LINUX, LÖSCHEN VON BUILD DEPENDENCIES
FROM python:3.8-alpine
COPY requirements.txt /requirements.txt
RUN apk update && apk add --no-cache --virtual .build-deps gcc python3-dev musl-dev linux-headers postgresql-dev && \
apk --no-cache add libpq && \
pip install -r /requirements.txt && \
apk del .build-deps
COPY src /app
WORKDIR /app
Das nächste auf Alpine Linux basierende Dockerfile fügt im Grunde auch nur ein Löschen von Build Dependencies hinzu, also von zusätzlich installierten Packages, die nur für das Builden des Images benötigt werden, nicht aber für das Ausführen der Anwendung. Damit das in nur einer Anweisung funktioniert, muss die COPY-Anweisung für die pip-Requirements nach oben geschoben werden, um das Installieren der pip-Requirements zwischen dem Installieren und Löschen der Build Dependencies durchführen zu können.
DOCKERFILE 5 - ALPINE LINUX, MULTI-STAGE
FROM python:3.8-alpine as base
FROM base as builder
RUN apk update && apk add gcc python3-dev musl-dev linux-headers postgresql-dev
RUN mkdir /install
WORKDIR /install
COPY requirements.txt /requirements.txt
RUN pip install --prefix=/install -r /requirements.txt
FROM base
COPY --from=builder /install /usr/local
COPY src /app
RUN apk --no-cache add libpq
WORKDIR /app
Das letzte Dockerfile nutzt das Multi-Stage Pattern. Beide Stages nutzen das Alpine Linux Python Base Image. In der ersten Stage, builder, werden die benötigten Build Dependencies installiert, das Verzeichnis /install als WORKDIR genutzt sowie anschließend die pip-Requirements kopiert und installiert. Die zweite Stage kopiert nun den Inhalt aus dem /install-Verzeichnis der ersten Stage, kopiert den Code der Anwendung und installiert mit libpq noch ein Package, das für die Ausführung der Anwendung benötigt wird.
AUSWERTUNG DER RESULTIERENDEN GRÖSSEN
Folgende Tabelle zeigt die resultierende Größe der Docker Images für unsere fünf Dockerfiles:
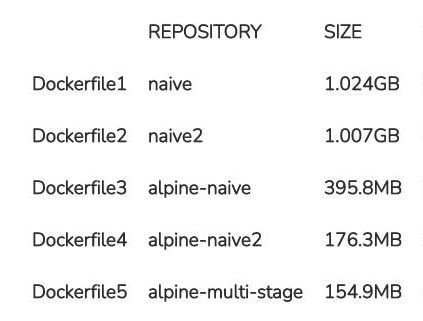
Den quantitativ deutlichsten Sprung kann man bei der Nutzung des Alpine-basierten Base Images beobachten. Sind die beiden Debian-basierten Docker Images noch jeweils über ein Gigabyte groß, spart die Nutzung von Alpine Linux über die Hälfte ein. Das daraus resultierende Image ist nur noch knapp unter 400 Megabyte groß. Durch geschickt geschriebene Anweisungen und somit optimiertere Dockerfiles können wir die Größe sogar mehr als halbieren und sind letztendlich bei 176 Megabyte.
Das Multi-Stage Dockerfile liegt bei knapp 155 Megabyte. Im Vergleich zum zuvor optimierten Dockerfile haben wir hier nicht allzu viel eingespart. Das Dockerfile ist durch die verschiedenen Stages zwar etwas umfangreicher, aber auch wesentlich aufgeräumter und wie weiter oben erläutert, mit den verschiedenen Stages deutlich flexibler. Mit diesem Image sind wir bei einer Größe von gerade mal 15% des ersten naiven Debian-basierten Images angelangt. Auch im Vergleich zum naiven Alpine-basierten Image haben wir mehr als 60% eingespart.
UNSERE EMPFEHLUNG: MULTI-STAGE DOCKERFILES
Unsere ganz klare Empfehlung ist die Verwendung von Multi-Stage Dockerfiles. Wie wir bei der Evaluation beeindruckend sehen können, lässt sich die resultierende Image-Größe dadurch deutlich reduzieren. Sofern es die Gegebenheiten und die Anwendung zulassen, sollte hinsichtlich der Image-Größe auch ein Alpine-basiertes Base Image verwendet werden.
Aber nicht nur aufgrund der resultierenden Image-Größe können wir Multi-Stage Builds empfehlen. Vor allem die Flexibilität durch die verschiedenen Stages ist aus unserer Sicht ein großer Pluspunkt. Damit können wir unseren Entwicklungsprozess bis hin zum Production-Deployment mit nur einem Dockerfile unterstützen und müssen nicht mehrere Dockerfiles maintainen.
Hast du noch Fragen oder eine Meinung? Mit deinem GitHub Account kannst Du es uns wissen lassen...
Hier sind ein paar Artikel, die du auch interessant finden könntest:

Kubernetes Backup in Storage Buckets
Wir nutzen neben Kubernetes auch Cloud Storage, Cloud SQL und GitHub Actions, um unsere Anwendungen effizient zu betreiben – und zu sichern. In diesem Artikel zeigen wir dir, wie du eine zuverlässige Kubernetes Backup Strategie umsetzt, um Datenbanken, Medien und Code vor Verlust zu schützen.

Django-CORS: Sicherheit & Best Practices
CORS (Cross-Origin Resource Sharing) richtig zu konfigurieren, ist entscheidend für die Sicherheit und Funktionalität deiner Django-Anwendung. Erfahre, wie du Django-CORS effektiv einsetzt, um externe Anfragen sicher und zuverlässig zu handhaben.

Elasticsearch: Die leistungsstarke Suchlösung für deine Daten.
Elasticsearch ist eine Open-Source-Such- und Analyse-Engine, die auf Apache Lucene basiert. Sie ermöglicht es, große Mengen an Daten in Echtzeit zu durchsuchen und zu analysieren. In diesem Artikel werfen wir einen genaueren Blick auf Elasticsearch, erkunden seine wichtigsten Funktionen und zeigen dir anhand von Praxisbeispielen, wie du Elasticsearch in dein Projekt integrieren kannst.

Effiziente Betriebszeiten mit KEDA: Dynamisches Autoscaling für Kubernetes-Cluster
Kubernetes ist leistungsstark, doch ohne optimierte Betriebszeiten können unnötige Ressourcen und Kosten entstehen. KEDA (Kubernetes Event - Driven Autoscaling) ermöglicht es, Workloads dynamisch zu skalieren und z.B. außerhalb definierter Betriebszeiten zu pausieren. In diesem Blogpost zeigen wir, wie du mit KEDA deinen Cluster an Arbeitszeiten anpasst – für mehr Effizienz und reduzierte Hosting-Kosten.

Kubernetes Skalierung in der Google Cloud
In diesem Artikel geht es um die Möglichkeit, Kubernetes Workloads in der Google Cloud einfach und nachhaltig zu skalieren.

Docker Desktop und Kubernetes
In diesem Artikel werfen wir einen Blick auf Docker Desktop im Jahr 2023 und konzentrieren uns darauf, wie Entwickler mit Kubernetes veröffentlicht. Wir möchten die bequemste Entwicklererfahrung ("DX") für Kubernetes-basierte Entwicklungsworkflows bieten, und Docker Desktop könnte eine gute Grundlage sein. Dann schauen wir es uns an.
Was unsere Kunden über uns sagen






- Ofa Bamberg GmbHB2B Online-Shop | B2C Website | Hosting | Betreuung | Security© Ofa Bamberg GmbH
- Ludwig-Maximilians-Universität MünchenPlattformentwicklung | Hosting | Betreuung | APIs | Website
Blueshoe hat unsere Forschungsdatenplattform Munich Media Monitoring (M3) entwickelt und uns hervorragend dabei beraten. Das Team hat unsere Anforderungen genau verstanden und sich aktiv in die Ausgestaltung der Software und der Betriebsumgebung eingebracht. Wir sind froh, dass auch Wartung und weiterführender Support in Blueshoes Händen liegen.
- Deutsches MuseumDigitalisierung | Beratung | Datenbank-Optimierung | GraphQL | CMSFoto: Anne Göttlicher
Im Rahmen eines komplexen Digitalisierungsprojekts für unsere Exponate-Datenbank war Blueshoe ein äußerst verlässlicher Partner. Sie haben uns nicht nur während des gesamten Projekts hervorragend beraten, sondern unsere Anforderungen perfekt umgesetzt. Dank ihrer Arbeit ist unsere Datenbank nun ein bedeutender Mehrwert für die weltweite wissenschaftliche Forschung.
- Fonds Finanz Maklerservice GmbHPlattformentwicklung | Prozess-Systeme | Hosting | Betreuung | Zertifikate | Website© Fonds Finanz Maklerservice GmbH
Blueshoe ist unsere verlängerte Werkbank für Entwicklung, Wartung und Support unserer Weiterbildungs- und Zertifizierungsplattformen. Das Team hat sich gründlich in unsere Abläufe eingearbeitet, und wir freuen uns, Blueshoe als zuverlässigen Partner an unserer Seite zu haben.
- Technische Universität HamburgPlattformentwicklung | Beratung | Prozess-Systeme | Hosting | Website
Seit 2019 unterstützt uns die Blueshoe GmbH tatkräftig bei der Entwicklung und Weiterentwicklung des "Digital Learning Lab" und der "Digital Learning Tools". Dank ihrer Beratung konnten wir von Anfang an auf eine zukunftssichere, moderne technische Struktur setzen. Die Zusammenarbeit ist reibungslos, und wir fühlen uns rundum gut betreut. Und davon profitieren dann auch die Lehrkräfte in Hamburg.




